
Technology
Basis Platform
Advertising Operating System
Communication Portal
Intelligent Collaboration
All Channel Activation
Activate Media on Every Channel
Consulting
Resources
Big data is like teenage sex; Everyone talks about it, nobody really knows how to do it, everyone thinks everyone else is doing it, so everyone claims they are doing it.
— Dan Ariely, Professor of Psychology and Behavioral Economics, Duke University
Information is the oil of the 21st century, and analytics is the combustion engine.
— Peter Sondergaard, Gartner Research
Everywhere you look these days, machine learning is in the news. A familiar buzzword, most people have heard it enough by now to know it has something to do with computers and algorithms, but that’s about it. But as we noted on this very blog, 97% of marketing influencers are predicting machine learning is the future of marketing. In fact, according to Google Trends, interest in the phrase has been increasing steadily over the last year, and right now machine learning has never been more popular. Other data supports this point. According to LinkedIn's 2017 U.S. Emerging Jobs Report, machine learning engineer is now the fastest-growing position. Furthermore, annual conferences dedicated to either machine learning or AI have now swelled to 243. And if we are to believe Fortune magazine, machine learning is no longer merely a trend, but a veritable revolution “electrifying the computing industry.”
So what’s all the buzz about? Why has machine learning become so popular? More importantly, why now? What is it about this point in time that makes it particularly ripe for a machine learning revolution? In this post, we demystify machine learning not only by defining it, but also illustrating how it evolved over time to fuel some of the most innovative technology today. In short, we show that all the buzz around machine learning isn’t just hype and that a revolution is happening in the computing industry being driven by machine learning.
Almost six decades ago, Arthur Samuel, widely regarded as the father of machine learning, first defined machine learning as a subfield of computer science that “gives computers the ability to learn without being specifically programmed.” While this definition is a good start, Alex Tellez, a self-described “machine learner” and author of Mastering Machine Learning with Spark 2.0, provides a more accessible definition. Alex defines machine learning as the “development, analysis, and application of algorithms that enable machines to make predictions and/or better understand data.”
But let’s unpack this a bit. What do we mean by make predictions or better understand data?
Normally, to solve a problem on a computer, we need an algorithm, which is simply a set of instructions that will transform an input into an output. But for some tasks, we actually lack an algorithm.
Take for example the problem of trying to be able to tell spam emails from legitimate emails. In this scenario, we know what the input is—an email—and we have a good idea as to what the output should be–a yes or no indicating whether the email is spam or not. But this is exactly where it gets more complicated: we still don’t know how to transform the input into the output because spam is constantly changing over time and from individual to individual. More broadly, as Ian Goodfellow, Yoshua Bengio and Aaron Courville suggest in their work Deep Learning, “The true challenge to artificial intelligence proved to be solving the tasks that are easy for people to perform but hard for people to describe formally—problems that we solve intuitively, that feel automatic, like recognizing spoken words or faces in images.” In other words, all of us intuitively know what spam is when we see it in our email inbox, but would we be able to describe it, i.e., draft a set of instructions for how to detect it?
This is where machine learning steps in. At root, machine learning allows us over time to transform input into outputs for tasks and applications for which there is no set of instructions, such as the spam detection task. Specifically, machine learning simply allows computers to learn without being programmed to do so and machine learning focuses on developing computer programs that can self-teach to change and grow when new data is introduced.
To see how this works in practice, let’s go back to the spam detection task. We can safely say that although we may lack algorithms for many tasks, we do however have massive amounts of data to help computers learn. Using data, we can begin to identify patterns or regularities that can help us to generate a useful approximation of the process. Assuming the near future doesn't change drastically, these patterns in data can help us to understand a process or even help us to make predictions that have a higher probability of being correct.
In the case of the spam email detection example, we can solve the problem with machine learning: a simple machine learning algorithm called Naive Bayes can distinguish between legitimate email and spam.
Machines can now perform complicated cognitive tasks that until recently only humans were capable of performing–such as driving cars, beating professional chess players, and even judging a song competition. In this sense, they’ve come a long way since the factory floors and manufacturing plants of the Industrial Revolution. But the history of a complex subject like machine learning, ironically enough, actually begins in many ways begins with a simple game of checkers.
Although Alan Turing had already created the Turing Test to determine if a computer has real intelligence in 1950, it wasn’t until 1952 that the first machine learning program was developed by Arthur Samuel. And by 1957 the first neural net was created for computers that simulated the thought process of the human brain. However, with the publication of his landmark study in 1959, “Some Studies in Machine Learning Using the Game of Checkers” Samuel introduced machine learning as a subfield of computer science.
While there was some progress between 1960 and 1989–such as the “nearest neighbor” algorithm that allowed computers to recognize patterns as well as Gerald Dejong’s Explanation Based Learning which enabled computers to analyze training data and create a general rule from it in 1981–things didn’t start to really heat up until the 1990s, when a paradigm shift occurred in the field, shifting focus away from knowledge and onto data. This is when scientists essentially started creating programs for computers to analyze large amounts of data and “learn” from the results and modern machine learning was born. Indeed, one of the most significant developments occurred in 1997 when IBM’s Deep Blue became the first chess-playing program to beat a reigning world chess champion at both a game and a chess match.
Fast forward to 2006, and Geoffrey Hinton, the man now credited with helping Google make AI a reality, coined the term deep learning to describe new algorithms that finally enable computers to “see” objects and texts in images and videos. Hinton went on to become a lead scientist at the Google Brain AI team and in 2011 developed a neural network that can learn to categorize objects.
Because Hinton’s postdoc students have all gone on to lead AI labs at Apple, Facebook and OpenAi, it should come as no surprise that in 2014, Facebook developed DeepFace, an algorithm capable of recognizing or verifying individuals on photos the same way humans can. And in 2015, Amazon not only launched its own machine learning platform, but Microsoft also launched its open-source Deep Learning Toolkit, which efficiently distributes machine learning problems across multiple computers. This tool kit allows almost anyone with a laptop and an Internet connection to become a machine learning expert, moving us one step closer to the democratization of machine learning.
Interest in machine learning took a dark side in 2015 when the Future of Life Institute published an open letter implicitly suggesting existential risk from advanced artificial intelligence–signed by both Stephen Hawking and Elon Musk along with 8,000 other AI and robotics researchers. However, a second open letter drafted in August of 2017 by Musk and 115 other experts to the U.N. explicitly warned of the dangers of using lethal autonomous weapons that are threatening “to become the third revolution in warfare.”
As Google Trends tells us, machine learning is at peak popularity and has virtually exploded in 2016 and 2017. But why is it so popular now, given that the field of study is at least 60 years old? What factors are converging to make this historical moment especially good for machine learning?
1. Mature Field: Both the identity and the methodologies of the field have matured in the last decade and that maturation has accelerated in the last few years. Although machine learning was once primarily a methodology under the larger discipline of artificial intelligence, it's now become a discipline in its own right because it's come to rely more heavily on the field of statistics. Moreover, the tools and methods used in the field of machine learning have also been maturing for the last 20 years.
2. Volumes of Stored Data: Arguably the single greatest factor contributing to machine learning’s mainstream appeal is the sheer abundance of stored data, which is rapidly growing. Machine learners simply have more data to “play” with, i.e., learn from. You often hear people complain now of “information overload” or “data exhaustion” largely because the systems and tools we use almost every day are generating data. And we’ve never collected data for individuals on this scale before. There are now groups such as QuantifiedSelf who are exploring all the ways you can track the collection of everyday information, such as heartbeats and even breath. If this trend continues, by 2025, we’ll be creating 163 Zettabytes of data every year.
3. Computational Processing Power: The simple answer is that computation is now also abundant and cheap. While only corporations used to have access to large computers with powerful processing, that’s all changed. With hosted infrastructure, you can now rent powerful computers for a few dollars an hour to run large experiments on immense data sets that you could never perform on a workstation or home PC.
4. Affordable Data Storage: And one of the most obvious reasons is that it’s simply become cheaper to store data. Data has to “live” somewhere. And with large datasets, it used to be very expensive to store data. No longer. Cloud-based machine-learning solutions from the big three public cloud providers: Google, AWS, and Microsoft make it affordable for almost any enterprise now to get involved in machine learning.
Machine learning is essentially a solution to more intuitive problems that lack a specific set of instructions, allowing computers to learn from experience and understand the world in terms of a hierarchy of concepts. Computers come to understand the world around them by defining concepts through their relation to simpler concepts. When computers accumulate knowledge from experience, rather than through a set of instructions, human operators no longer need to formally specify all the knowledge a computer needs.
In each case, the computer learns complicated concepts because of their nested relationship to simpler concepts. A graph drawn that would illustrate exactly how these concepts are built on top of each other would have many layers.
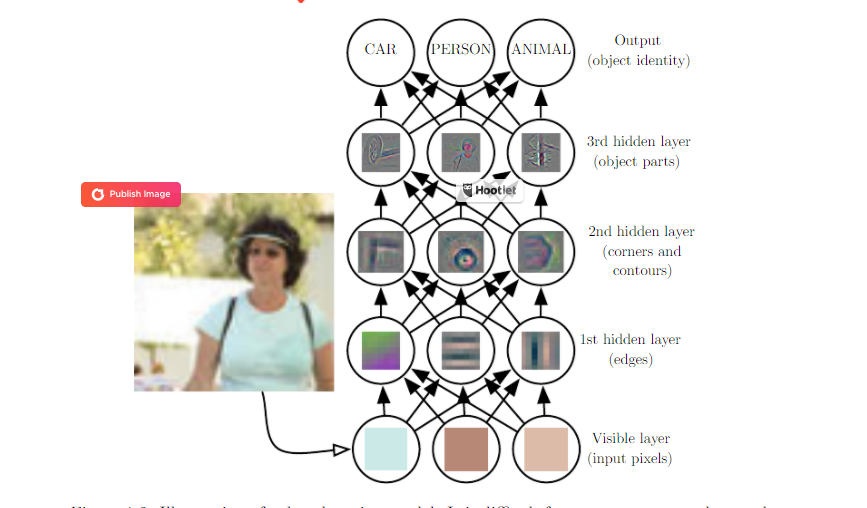
The image above, taken from Ian Goodfellow, Yoshua Bengio and Aaron Courville’s work on deep learning, illustrates just how difficult it is for a computer to understand raw sensory input data. In actuality, although humans are able to easily identify people and their faces, function mapping from a set of pixels to an object identity is very complicated: “Learning this mapping would be almost impossible if handled directly, but deep learning resolves this by breaking the desired complicated mapping into a series of nested simple mappings, each described via different layer in the model.” In this model, the input is called the visible layer because it contains variables we can observe. In between the output layer and input layer are hidden layers that extract abstract features from the image. We label these layers “hidden” because their values aren’t present in the data but must be determined by the model when it seeks to uncover which concepts are best at explaining certain relationships in the data.
This example can help us to see why this particular approach to machine learning is often called “deep learning.”
Machine learning is used in Financial Services, Healthcare, Government, Marketing and Sales, Oil and Gas, and Transportation among others. While there are many applications for machine learning, below I’ve provided three of the most popular:
Learning Associations—Retail Cross-Selling
In retail, a common application of machine learning is basket analysis. Basket analysis involves finding associations between products bought by customers and developing an association rule from statistical probability to enable cross-selling.
For example, if customer X happens to frequently purchase product Y, and if a customer X can be identified who doesn’t yet purchase Y, he or she is an excellent candidate to cross-sell product Y. More plainly, if X happens to purchase beer and customers like X also happen to frequently purchase chips with beer, then an association rule—70% of customer who buy beer also buy chips– can be developed via machine learning to enable cross-selling to X.
Classification—Financial Risk Assessment
Classification in machine learning builds on associations and goes a step further to identify group membership. A common application of classification is when banks try to predict in advance the risk of a bank loan. What is the risk that the customer will default and not pay the loan back? Which applications belong to a high-risk group and which belong to a low risk group? The way the bank calculates the risk is by looking for patterns in data about past customer loans as well as information regarding a customer’s financial history—income, savings, collateral etc– in order to make a prediction about the future. The bank fits a model of past data in order to calculate the risk of a new application, making a decision to accept or refuse the risk.
In this example, two classes are established, low risk and high risk, and the job of the classifier is to assign the input (the customer) into one of two classes:
IF income > 01 and savings is >then low risk ELSE high risk
Once a classification rule has been established the primary application is prediction. Assuming the future is similar to the past, if we have a rule that fits past data, then we’re able to make predictions about new instances in the future. In the case of a bank loan, the classification rule will enable the loan qualifier to evaluate a loan application with certain income and savings and quickly decide if the loan is low or high-risk. As such, a classification rule in machine learning is a tremendously powerful risk assessment tool for financial institutions.
Regression—Medical Mortality Prediction
Unlike classification, regression involves estimating or predicting a response or output value not from a membership in a group, but from a continuous set of training data. In other words, given a set of data, find the best relationship that represents the set of data.One of the most exciting examples of regression being used is machine learning for the healthcare industry. Machine learning algorithms can help medical experts analyze data to identify trends or red flags that may lead to improved diagnoses and treatment.
By analyzing the data from past cases to understand the risk factors that contribute to a certain patient outcome or diagnosis, these algorithms can ingest the data of a new patient and compare it to the models developed with the training set to predict the likely outcome. In the case of predicting clinical outcomes for patients diagnosed with a stroke, clinicians can use machine learning for creating diagnostic scores that will more accurately predict an outcome. According to a recent study, strokes account for “5.54 million deaths worldwide” and are the second commonest cause of mortality. A quick and accurate diagnosis of a stroke is important for immediate resuscitation. Using a free and easy-to-use “exploratory regression technique’, researchers were able to predict a 30-day mortality rate following a stroke in the rural Indian population that was 14% more accurate than existing scores.